
Le machine learning, c’est quoi ?
Le machine learning ou apprentissage automatique est un sous-ensemble de l’intelligence artificielle. Il crée des systèmes qui ont la capacité d’apprendre et de s’améliorer par eux-mêmes sans programmation explicite. Grâce à des données existantes, il peut réaliser des estimations et prédictions.
L’un des principaux intérêts de cette technologie est l’automatisation des tâches.
Pour apprendre, il a besoin de consommer des big data et son succès réside dans l’entrée d’un volume considérable de données.
L’adaptive learning repose sur le machine learning. C’est un exemple de sa mise en application au service de l’enseignement digital. Un autre domaine découle de notre sujet : le Deep Learning.
Aujourd’hui, nous utilisons le machine learning dans de nombreux domaines. Ces algorithmes entrent en jeu pour optimiser, fluidifier et sécuriser notre expérience lors d’achats en ligne, d’utilisation de réseaux sociaux, d’interactions avec les banques… L’intervention de cette innovation a aussi lieu dans la recommandation de produits, la traduction automatique ou encore les véhicules autonomes.
Le fonctionnement du machine learning
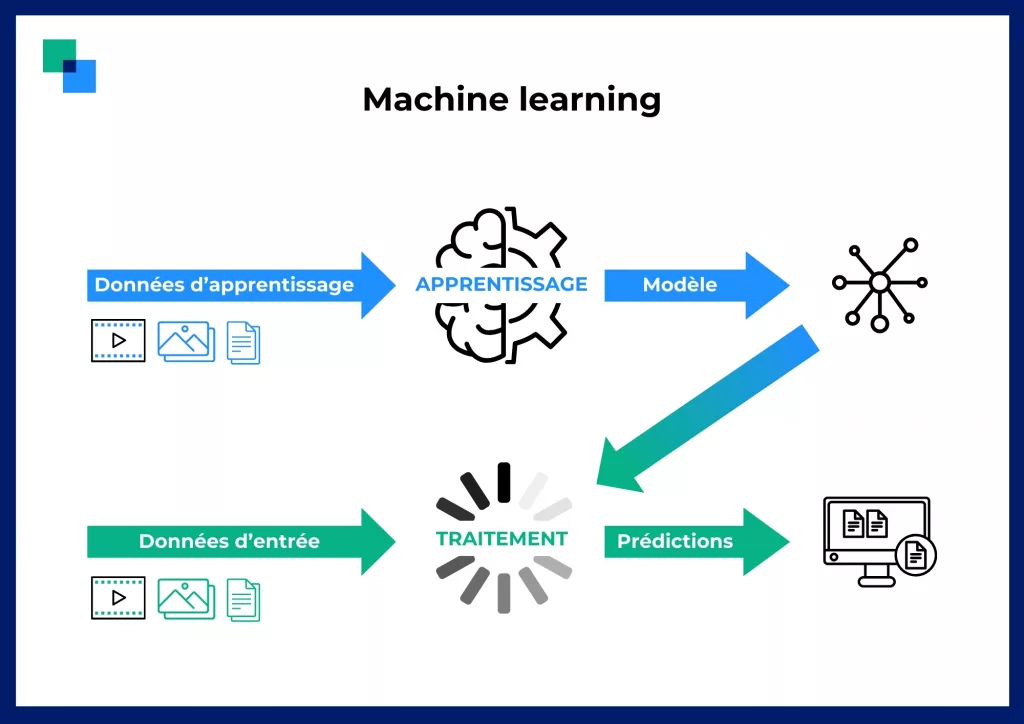
Le machine learning consiste à entraîner un algorithme au sein d’une base d’apprentissage. On lui fait reconnaître des motifs récurrents ou « patterns » pour aboutir à un modèle réalisant des prédictions.
Une fois ce modèle développé, celui-ci est sollicité par la machine lors de traitements de nouvelles données, pour aboutir à une réponse ou à une action finale. Au fur et à mesure des entraînements successifs et grâce à l’évolution du contexte, l’algorithme améliore ses performances.
Tout ce processus à lieu automatiquement et vous n’aurez qu’à renseigner les données initiales pour l’apprentissage ! Plus on le nourrit et plus il devient précis.
Les différents types de machine learning
Apprentissage supervisé
Le machine learning supervisé est une technologie élémentaire stricte. Des exemples de données d’entrées et sorties sont fournies à l’ordinateur pour que celui-ci cherche les moyens d’arriver à ces sorties selon les entrées. Le but est qu’il apprenne une règle générale mappant les entrées et sorties.
Les données fournies à l’appareil sont le plus souvent étiquetées pour qu’il puisse savoir quels modèles il doit chercher. La phase d’apprentissage est donc accompagnée et elle nécessite moins de données que pour les autres types de machine learning.
L’apprentissage supervisé fait des prédictions précises sur des données futures ou indisponibles. Cette modélisation prédictive peut être catégorisée en deux types :
- Classification : les résultats de sortie se présentent sous forme de catégorie
- Régression : les résultats de sortie sont des valeurs spécifiques
Les principaux algorithmes du machine learning supervisé sont : les arbres à décision, les forêts aléatoires, le boosting gradient, la régression linéaire, la machine à vecteurs de support (SVM), les algorithmes K-NN…
Apprentissage non supervisé
Le machine learning non supervisé est aussi appelé « apprentissage des caractéristiques » ou « feature learning ». Il permet de déterminer lui-même les données d’entrée. Elles ne sont pas étiquetées et l’appareil les parcourt pour identifier des modèles.
Cette approche permet d’identifier des structures ou des relations de données présentes en entrée du processus.
On peut définir trois types d’apprentissage non supervisé :
- Clustering : les données sont regroupées de façon homogène dans des groupes ou clusters
- Association de dimensionnalité : les règles qui permettront de définir des grands groupes de données sont identifiées
- Réduction de dimensionnalité : les variables d’un groupe de données sont réduites sans altérer la transmission des informations importantes
Les principaux algorithmes du machine learning non supervisé sont : K-Means, réduction de la dimensionnalité et clustering/regroupement hiérarchique.
Apprentissage semi-supervisé
Le machine learning semi-supervisé se situe entre les deux méthodes que l’on vient de mentionner. L’algorithme reçoit des données étiquetées pour enrichir celles non étiquetées. Elles guident la classification et l’extraction des caractéristiques de l’ensemble des informations. Cela permet à l’appareil d’avoir une longueur d’avance qui améliore la vitesse et la précision de l’apprentissage.
Ce machine learning semi-supervisé est utile lorsque l’on ne possède pas assez de données étiquetées. Cette solution contourne le problème.
Apprentissage par renforcement
Le machine learning par renforcement est un programme qui interagit avec un environnement dynamique. Au sein de celui-ci, il doit réaliser une tâche précise, un but. Il reçoit des feedbacks sous forme de « récompense » ou de « punition » en fonction de l’action qu’il aura choisi d’effectuer. Cela lui permet d’apprendre à reconnaître le comportement le plus efficace dans un contexte donné.
Par exemple, dans un jeu vidéo, le but peut être de conduire un véhicule ou de combattre un adversaire. Les algorithmes arrivent à réaliser les actions les plus optimales en apprenant de leurs erreurs. C’est ainsi qu’AlphaGo a pu battre le champion du monde de Go !
Il y a deux types d’apprentissage par renforcement :
- Monte-Carlo : le programme reçoit ses récompenses uniquement à la fin
- Machine learning par différence temporelle (TD) : les récompenses sont données à chaque étape
Pour aller plus loin
Qu’est-ce que le Machine Learning ?
Machine learning : définition et fonctionnement






